Abstract
Variational inference techniques based on inducing variables provide an elegant framework for scalable posterior estimation in Gaussian process (GP) models. Besides enabling scalability, one of their main advantages over sparse approximations using direct marginal likelihood maximization is that they provide a robust alternative for point estimation of the inducing inputs, i.e. the location of the inducing variables. In this work we challenge the common wisdom that optimizing the inducing inputs in the variational framework yields optimal performance. We show that, by revisiting old model approximations such as the fully-independent training conditionals endowed with powerful sampling-based inference methods, treating both inducing locations and GP hyper-parameters in a Bayesian way can improve performance significantly. Based on stochastic gradient Hamiltonian Monte Carlo, we develop a fully Bayesian approach to scalable GP and deep GP models, and demonstrate its state-of-the-art performance through an extensive experimental campaign across several regression and classification problems.
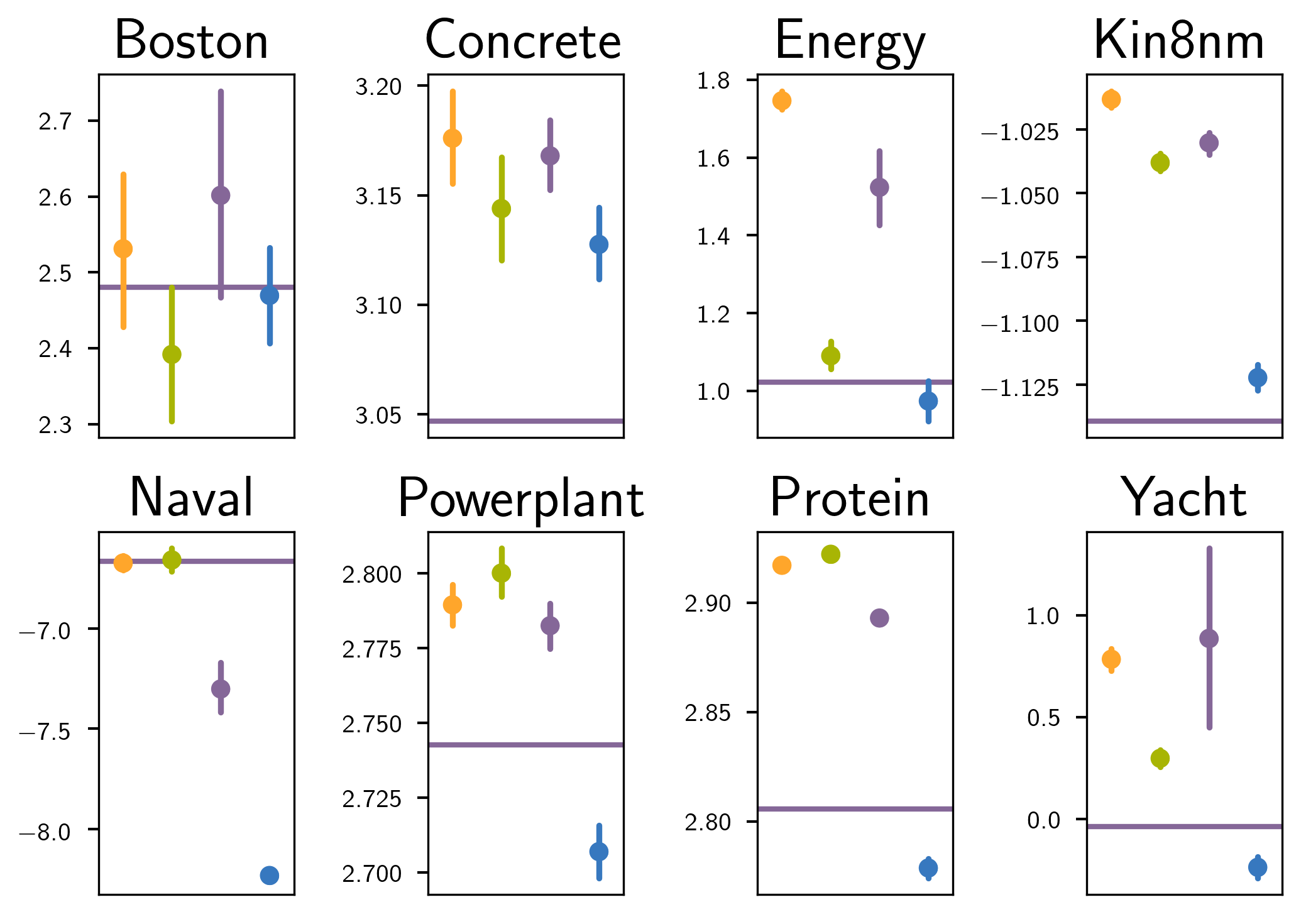
Key Contributions
Challenging optimization-based approaches: We question the prevailing assumption that optimizing inducing inputs in variational frameworks yields optimal performance for sparse Gaussian processes.
Fully Bayesian treatment: We propose treating both inducing locations and GP hyperparameters in a fully Bayesian manner, rather than relying on point estimates.
Sampling-based inference: We develop a framework based on stochastic gradient Hamiltonian Monte Carlo (SGHMC) for efficient posterior inference over inducing variables.
Revisiting classical approximations: We show that classical model approximations like fully-independent training conditionals (FITC), when combined with powerful sampling methods, can outperform modern variational approaches.
State-of-the-art performance: Through extensive experiments on regression and classification tasks, we demonstrate that our fully Bayesian approach achieves competitive or superior performance compared to existing methods.
Methodology Overview
The core insight of our work is that the point estimation of inducing inputs, while computationally convenient, may not be optimal for capturing the true posterior distribution in Gaussian process models. Instead, we advocate for:
Bayesian treatment of inducing locations: Rather than optimizing the positions of inducing points, we sample from their posterior distribution.
Joint inference over hyperparameters: GP hyperparameters are also treated as random variables and inferred jointly with the inducing locations.
Stochastic gradient Hamiltonian Monte Carlo: We leverage SGHMC to perform efficient approximate Bayesian inference in the large-data regime.
Classical approximations with modern inference: We revisit classical sparse GP approximations (such as FITC) and show that they become highly competitive when combined with sampling-based inference.
Main Findings
- Point estimates of inducing inputs may lead to suboptimal performance compared to full Bayesian treatment.
- Classical sparse GP approximations, when combined with sampling methods, can outperform modern variational approaches.
- The fully Bayesian approach provides better uncertainty quantification and robustness.
- SGHMC enables scalable inference even for large datasets.
- Our method achieves state-of-the-art results on various regression and classification benchmarks.
- The approach is applicable to both standard GP models and deep GP architectures.
Experimental Results
We evaluated our approach on a diverse set of regression and classification datasets, comparing against state-of-the-art variational inference methods and sparse GP approximations. Our experiments demonstrate:
- Regression tasks: Competitive or superior performance on standard UCI datasets.
- Classification tasks: Strong results on binary and multi-class classification problems.
- Deep Gaussian Processes: The approach extends naturally to deep GP models.
- Uncertainty quantification: Better calibrated predictive uncertainties compared to point-estimate methods.
References
Rossi, S., Heinonen, M., Bonilla, E., Shen, Z. & Filippone, M.. (2021). Sparse Gaussian Processes Revisited: Bayesian Approaches to Inducing-Variable Approximations. Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, 130, 1837-1845. PMLR.